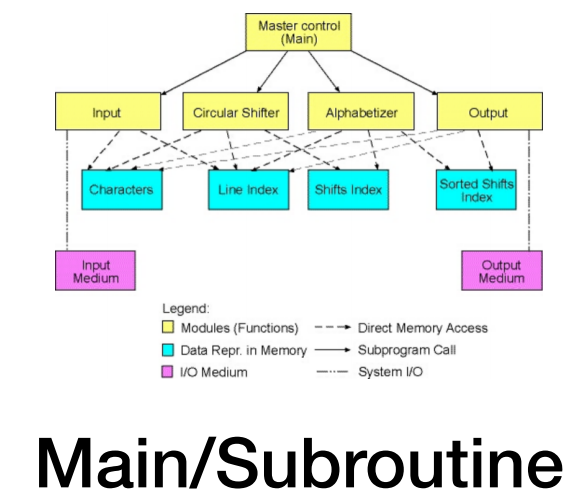
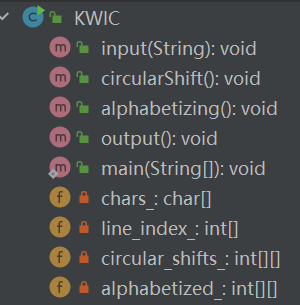
KWIC是"Keyword in Context"(关键词上下文)的缩写。 KWIC是一种文本分析方法,用于提取文本中的关键词并在其周围显示一定数量的上下文信息。这通常被用于索引和搜索系统中的文本数据,以便用户可以快速找到与其关注的关键词相关的文本。KWIC索引通常显示在一个表格或网格中,其中每一行都是一个关键词及其周围的文本片段,让用户可以快速浏览文本内容,快速找到感兴趣的信息。
/** * Input function reads the raw data from the specified file and stores it in the core storage. * If some system I/O error occurs the program exits with an error message. * The format of raw data is as follows. Lines are separated by the line separator * character(s) (on Unix '\n', on Windows '\r\n'). Each line consists of a number of * words. Words are delimited by any number and combination of the space chracter (' ') * and the horizontal tabulation chracter ('\t'). The entered data is parsed in the * following way. All line separators are removed from the data, all horizontal tabulation * word delimiters are replaced by a single space character, and all multiple word * delimiters are replaced by a single space character. Then the parsed data is represented * in the core as two arrays: chars_ array and line_index_ array. * * @param file Name of input file */
publicvoidinput(String file) {
// 实现input // 期望处理后的目标 // All line separators are removed from the data, all horizontal tabulation // word delimiters are replaced by a single space character, and all multiple word // delimiters are replaced by a single space character. try { FileReaderinputFileReader=newFileReader(file); BufferedReaderinputFileBufferedReader=newBufferedReader(inputFileReader);